Vertical GEO is not just generic GEO applied to an industry
Generic GEO methodologies — built around user prompts as demand input, visibility and SOV as core metrics, and content distribution as deliverables — fit B2C exposure but map poorly to vertical industries. In pharmaceuticals, industrial goods, finance, and law, demand is better read from market data than from lagging prompts, and competition happens on the intermediate "semantic bridges" AI must traverse rather than at the endpoint of recommendation. Vertical GEO therefore requires different deliverables (authoritative-content restructuring, bridge coverage), different evaluation standards (accuracy, authority, scenario match over mention frequency), and a different supply chain (domain expertise plus AI-visibility technology, not a transplant of generic GEO skills).
Most generic GEO services today are built on a similar methodology: user prompts in AI as the input signal for demand, visibility / share of voice / citation rate as the core metrics, and content distribution plus reporting systems as the primary deliverables. Some mature providers have started to incorporate semantic analysis and scenario-based monitoring, but the dominant industry metrics still revolve around this axis. Transplanting this framework wholesale into pharmaceuticals, industrial goods, finance, law, and other vertical industries produces visible friction at almost every step.
The argument of this article is simple: vertical GEO requires a different methodology, different deliverables, and different evaluation standards.
1. Demand input — from "what users ask" to "what the market actually needs"
Generic GEO treats user prompting behavior as the compass for marketing investment. The assumption is reasonable for B2C, low-decision-cost, high-search-density categories. In vertical industries it has two limitations worth flagging.
First, prompt volumes lag; market data leads.
A user query to AI is a behavior that happens after demand has surfaced. Structural changes in the market — regulatory shifts, seasonal cycles, upstream supply chain moves, technology substitution — typically happen before the corresponding prompt activity. Demand for heat-stroke medication rises predictably as summer approaches; that signal is already visible in historical sales data. When a regional authority requires PCR content thresholds in plastic packaging, market data immediately reflects the upstream manufacturers' production-line upgrade demand. By the time prompt volumes "catch up," the faster-moving players have usually already positioned themselves.
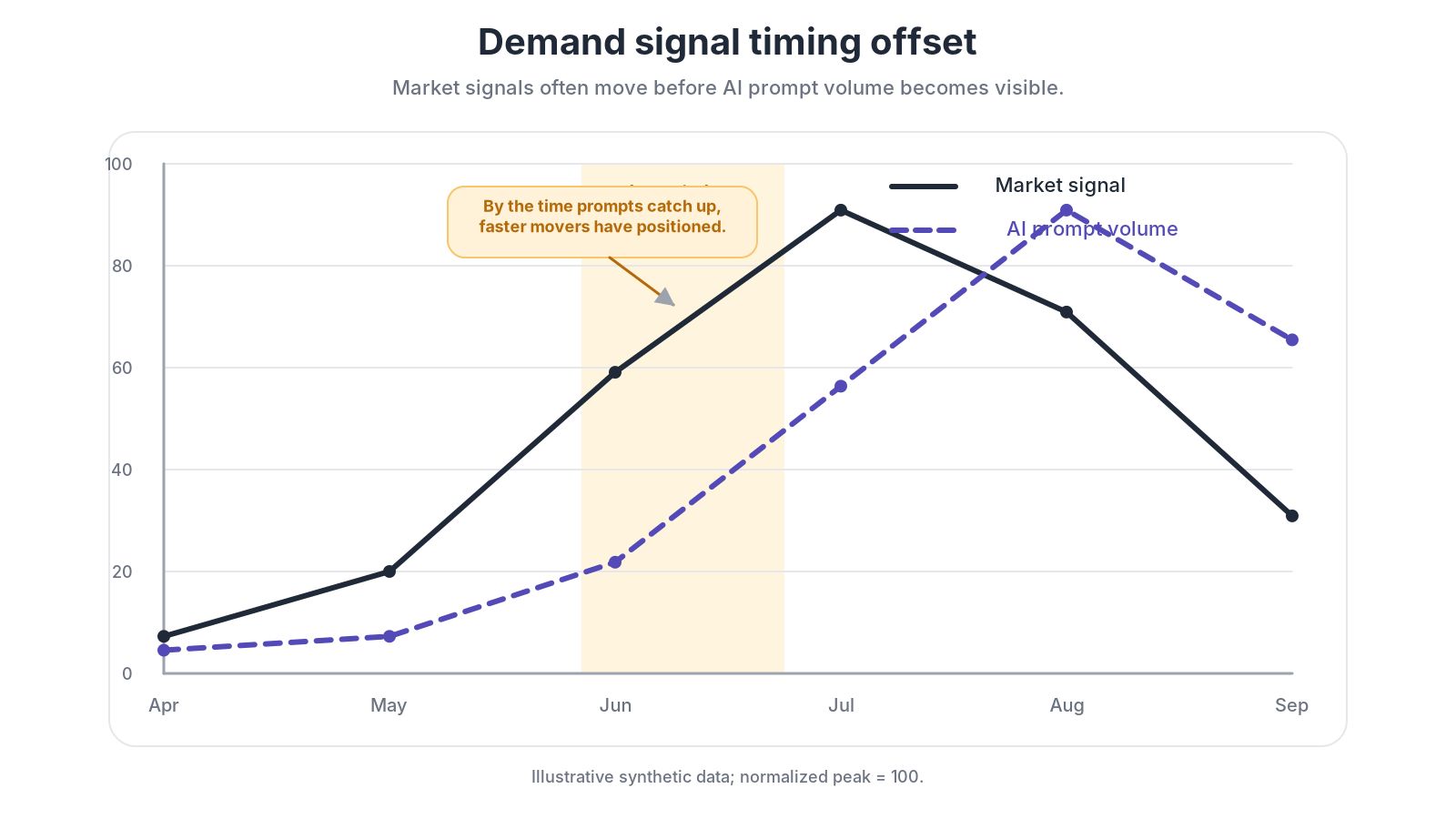
Second, the more vertical, more B2B, and more high-value the category, the weaker the statistical meaning of prompt volumes.
The total number of buyers for plastic-tube packaging equipment in China is perhaps a few hundred people. Even if every one of them sent ten queries to AI per day, the aggregate signal is close to statistical noise against any general web panel. But market data providers typically have clear visibility into those few hundred companies' capacity plans, procurement cycles, and capex schedules.
A more reliable approach is therefore to demote prompt volume — not eliminate it — from a primary demand source to one of several validation signals. The main axis returns to market data, business scenarios, and decision chains:
Define demand scenarios using market size, industry structure, policy and seasonality signals;
Generate the monitoring prompt matrix by combining user personas, business steps, and decision stages;
Use real user queries to validate the matrix's coverage and weighting after the fact.
Compared with unverifiable prompt-volume estimates, market-size, sales data, regulatory signals, and procurement cycles — drawn from third parties or from the enterprise's own systems — at least provide a more traceable basis for demand. The underlying logic is closer to audience coverage in advertising than to keyword search volume in SEO.
2. Deliverables — from "visibility" to "semantic bridges"
Generic GEO deliverables center on visibility, SOV, citation rate, and sentiment. These metrics matter in vertical industries too, but they cover only the trailing portion of where competition actually happens.
Take pharmaceuticals. For compliance and safety reasons, AI generally avoids making drug decisions on a user's behalf, but it is fairly active in explaining symptoms, pathology, mechanisms, clinical literature, and applicable use cases. The real work of pharma GEO therefore lies not at the terminal node "make AI recommend my drug" — which is neither realistic nor compliant — but along the entire semantic path from user need to AI's final answer:
User symptom → Pathology → Mechanism → Treatment logic → Pharmacology & formulation → Use case
We call the middle nodes on this path semantic bridges.
Definition. Semantic bridges are the set of professional explanation nodes AI must pass through as it moves from a user question toward any brand, product, therapy, or solution. They typically include conceptual definitions, etiology and mechanism, applicability conditions, evidence sources, limitations, and scenario judgments.
To make this concrete, consider a virtual anonymized example: an AI conversation triggered by "what should I do about post-meal upper-abdominal pain." The reasoning branches roughly as follows.
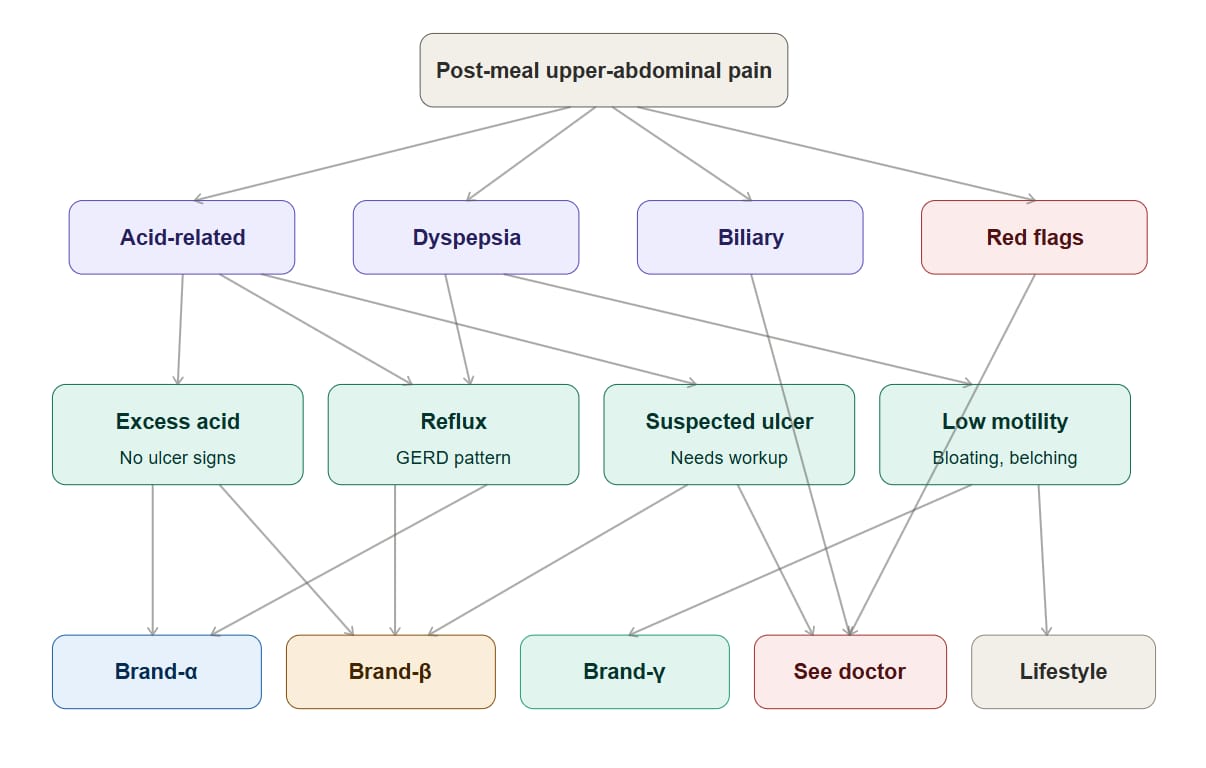
Many pharma companies in fact hold large volumes of high-quality clinical research and review materials. But their visibility in AI is often poor — either the materials were never indexed, or their format makes them hard to extract and cite. The core deliverables of pharma vertical GEO therefore tend to include: AI-friendly restructuring of authoritative source materials, clustering analysis of the intermediate semantic bridges in AI responses, and coverage repair for use-case scenarios.
Similar compliance and professional boundaries exist in finance (product education, not investment advice), law (legal-system education, not legal opinion), and aesthetic medicine (mechanism explanation, not efficacy claims). The specific delivery priorities differ across verticals — medicine and law center on compliance and authoritative explanation, industrial goods on working conditions, parameters, and procurement chains, finance on regulatory tone and risk education — but together they shift away from the exposure logic of generic GEO toward a stronger logic of professional cognition building. The common pattern can be summarized:
Generic GEO competes at the recommendation layer; vertical GEO competes at the explanation layer.
If we overlay simulated traffic onto the same reasoning skeleton — using virtual numbers to make the logic visible — the picture looks like this:
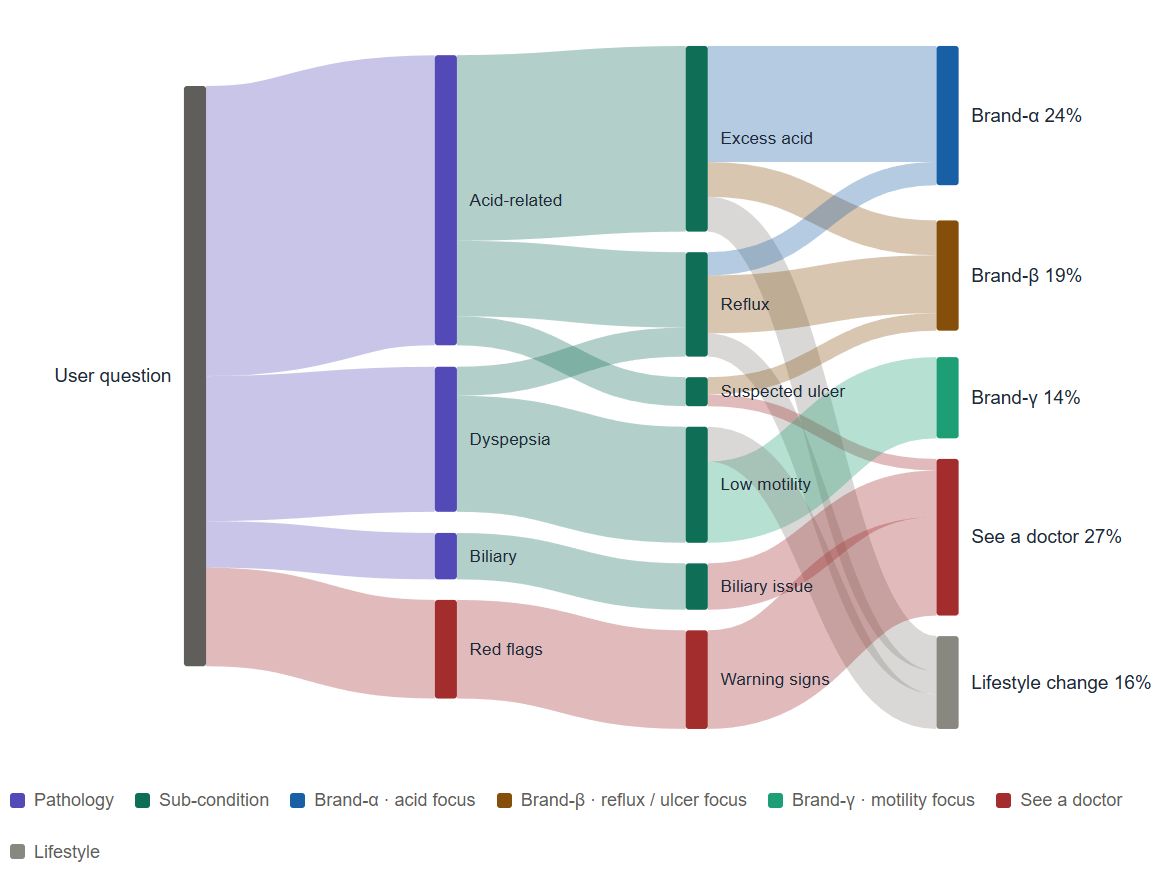
Read this carefully. At the endpoints, the three virtual brands look comparable — Brand-α 24%, Brand-β 19%, Brand-γ 14%. But on the middle bridges they live in completely different places. Brand-α occupies almost only "Excess acid." Brand-β dominates the "Reflux / Suspected ulcer" bridges. Brand-γ owns "Low motility" alone. Endpoint mention rate tells you who shows up; semantic-bridge occupancy tells you what AI thinks each brand is.
The same picture also explains where the two methodologies put their attention:
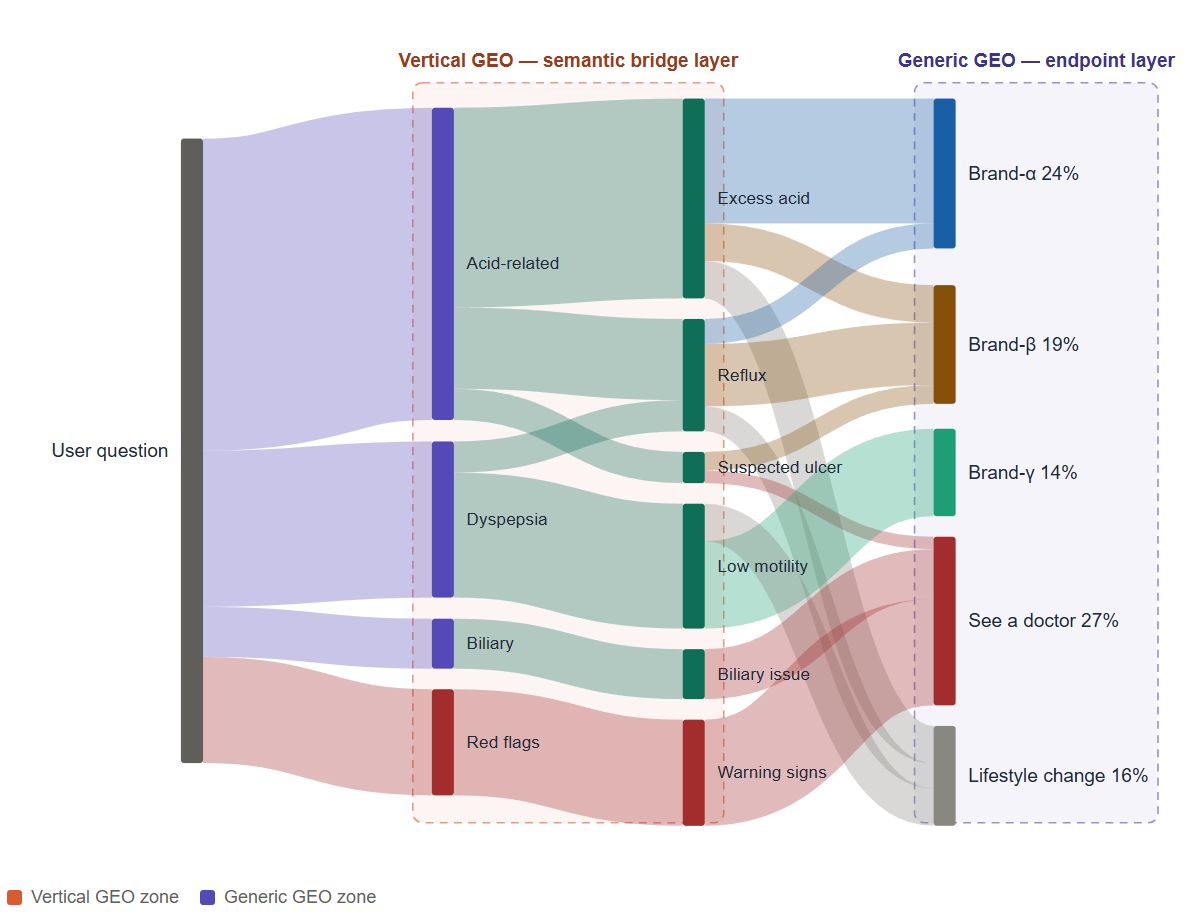
Generic GEO instrumentation reads the rightmost column. Vertical GEO instrumentation reads the middle two. These are not competing views; they look at the same picture and prioritize different layers.
This structure also addresses a recurring commercial difficulty for generic GEO providers: the outcome-oriented deliverables (one-off visibility, sentiment, citation reports) feel thin, and the process-oriented deliverables (content distribution, which in practice resembles a re-skinned version of SEO-era link building) struggle to convey distinct value. Semantic-bridge analysis, authoritative-content restructuring, and market-data mapping, by contrast, are deliverables that marketing teams genuinely need but usually cannot produce in-house or can only access through expensive consulting.
Step | Generic GEO approach | Vertical GEO approach |
Monitoring target | Endpoint prompts like "recommend a drug for X" or "what should I take for Y" | Full semantic chain: symptom → mechanism → indication → guideline → evidence |
Problem diagnosis | Brand mention rate in AI is low | AI's mechanism explanations are incomplete; brand's own clinical materials are not in the cited sources |
Optimization action | Produce more content; build more outbound links | Restructure clinical review pages; reorganize evidence; add condition-education content |
Evaluation metrics | Mention rate, citation rate | Semantic-bridge coverage, authoritative-citation rate, compliance-accuracy rate |
Mention rate and citation rate remain valid metrics in vertical GEO — they simply cannot answer the more central question of whether AI has accurately constructed a brand in professional cognition. The semantic-bridge coverage in the table above can be quantified as: decomposing the canonical explanation nodes of a condition or scenario into a standard checklist, counting how many of those nodes are correctly addressed in AI's response, and weighting by the authority of the cited sources.
Coverage is not uniform across bridges. The same picture, recolored by AI's actual authoritative coverage on each node, immediately reveals where the work is:
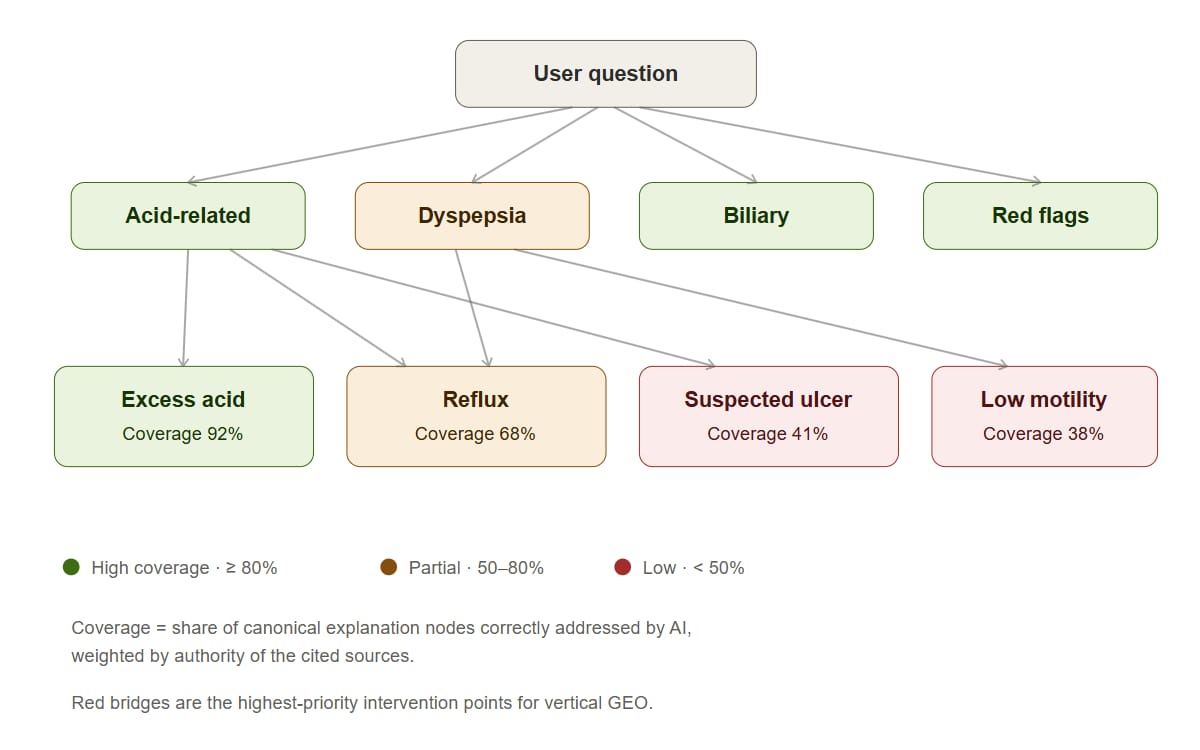
Red nodes are where vertical GEO should intervene first — not by pushing for endpoint mentions, but by restructuring authoritative content so the bridge itself becomes legible to AI. The intervention is observable downstream:
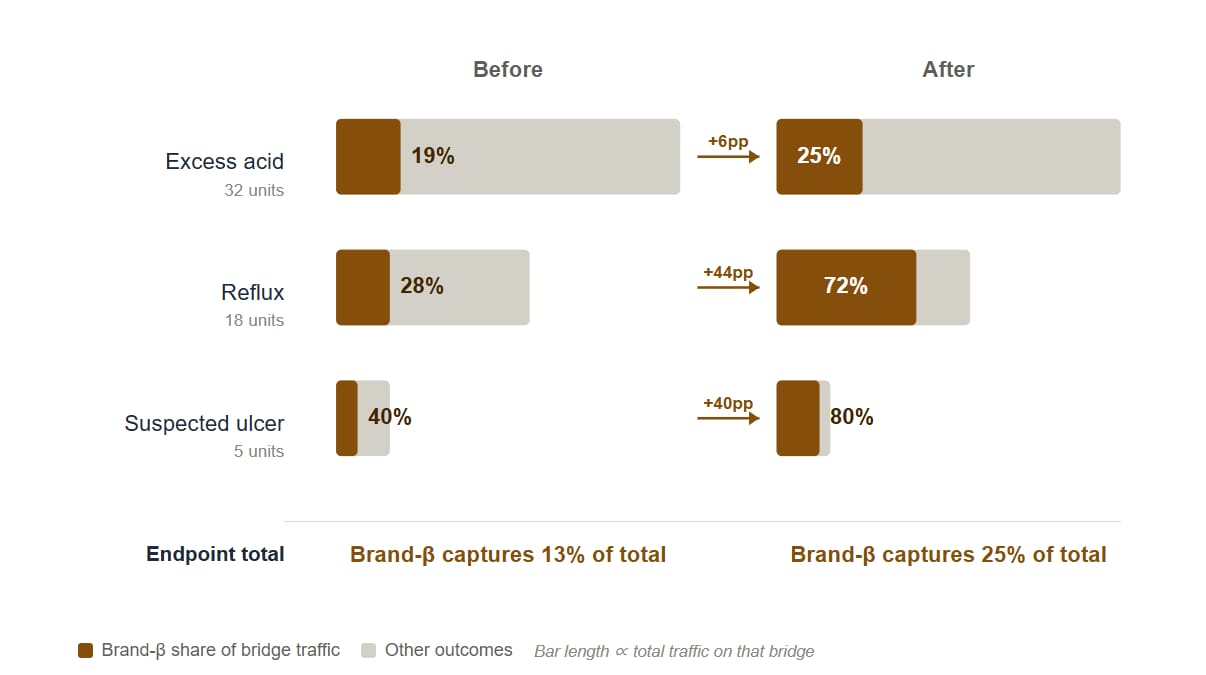
After a vertical-GEO intervention focused on Reflux and Suspected ulcer bridges, the biggest structural shifts happen on the bridges themselves — Reflux Brand-β share jumps from 28% to 72% (+44pp), and Suspected ulcer goes from 40% to 80% (+40pp). Excess acid changes much less, because Brand-β was never positioned there in the first place. Those three bridge-level shifts compound into the endpoint total moving from 13% to 25%. The endpoint number is real, but it is the consequence, not the cause.
And what does the underlying content composition look like for a single bridge? Roughly this:
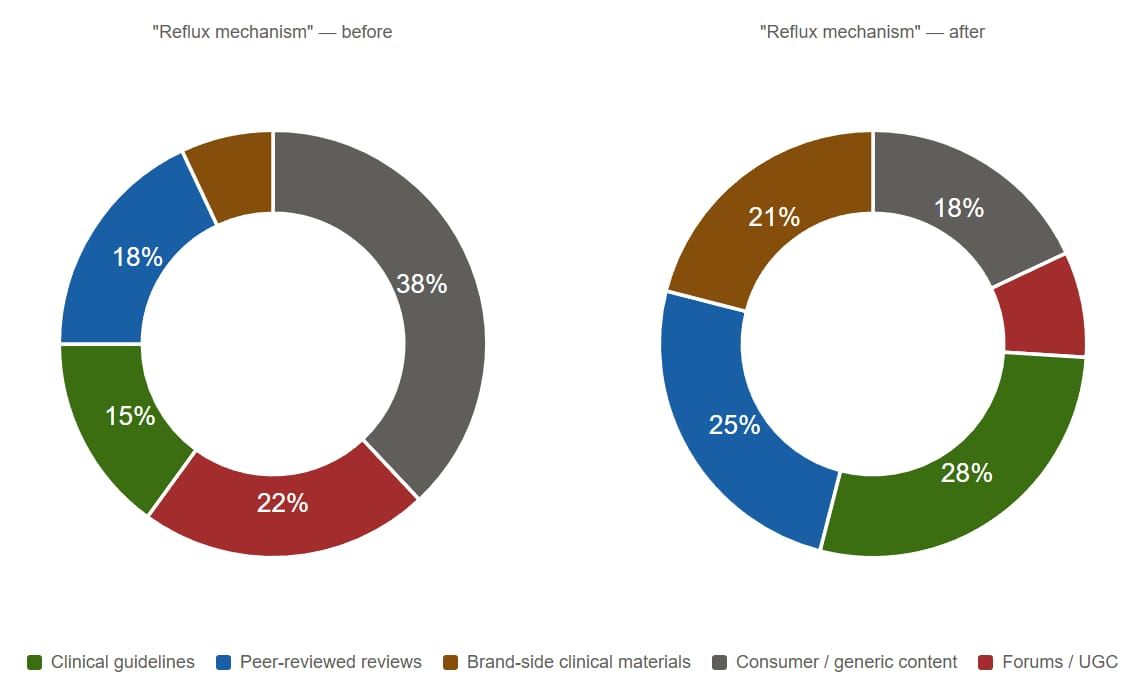
Before intervention, AI's explanation of "reflux mechanism" leans on consumer-grade content and forum / UGC — sources that are easy for AI to retrieve but weak in authority. After intervention, clinical guidelines, peer-reviewed reviews, and brand-side clinical materials become the load-bearing references. Total content volume is similar; the composition changes, and so does AI's confidence in citing the brand on this bridge.
3. Evaluation standards — success means different things
Generic GEO uses SOV and citation rate as primary metrics, reflecting a consumer-goods model of exposure → preference → purchase. Vertical success models usually emphasize different dimensions:
Pharmaceuticals: being explained accurately and compliantly > being mentioned frequently. High-frequency mention with inaccurate explanation is a negative asset.
B2B industrial goods: precise-persona match and accurate model selection > broad visibility. For an industrial gearbox manufacturer, being mentioned 100 times under generic prompts like "recommend an industrial gearbox" usually generates no inquiries, while being precisely recommended once under a specific scenario like "drive selection for a 500 kt/y cement-plant rotary kiln" corresponds directly to a sizable order.
Professional services: authoritative categorization > count of mentions. A law firm listed among the top three under "which firms are typically consulted on antitrust filings in cross-border M&A" is worth far more than appearing as the 15th item in a generic "top law firms" list. The former means AI recognizes the firm as an authoritative answer for that specific question; the latter only as one company in the industry.
4. Supply chain — capability bars that aren't always visible
The final difference is in content production capability itself. For vertical GEO to actually be cited by AI as an authoritative source, the content must meet the standards of the field: pharma content needs MD/PhD-level authors and conformance to medical citation norms; legal content must cite specific statutes and case rulings; financial content must comply with regulatory framing and stay clear of investment-advice territory; industrial-goods content usually requires engineer involvement and alignment with industry standards and operating-condition parameters.
Abstracting these requirements, the vertical-GEO supply chain depends on at least four largely independent capabilities:
Domain authors and subject-matter consultants;
Compliance review and citation-norm governance;
Structuring of authoritative content and AI-retrieval-friendly formatting;
Vertical-specific evaluation metrics and monitoring models.
These capabilities are typically outside the staffing and compliance footprint of generic GEO providers. Vertical GEO therefore sits closer to a combination of "domain know-how + AI-visibility technology" than to a tool or methodology transplant. This is also why the field is more likely to develop a set of vertical-specialized providers over time, rather than being absorbed by a single generic platform.
Summary
The core of vertical GEO is not transplanting generic GEO metrics into a specific industry. It is using market data to define demand scenarios, semantic bridges to decompose AI's reasoning path, authoritative content to rebuild citable assets, and vertical metrics to evaluate whether professional cognition has been correctly established. In that sense it is a methodology in its own right, not a localized version of generic GEO.